# 并行与并发
一段程序代码,执行了一个任务(Task),任务由一系列的操作(Operation)构成,包括:
- 实际占用 CPU 运算资源的操作
- 硬盘读写、网络传输等不占用 CPU 运算资源的 I/O 操作
对于第 2 类 I/O 操作,时间都花在了等待上,在这些操作期间 CPU 是空闲的状态
并行与并发都属于多任务处理,区别在于:
- 并行:同一时间执行多个任务。执行表示同一时间的多个任务中都在进行第 1 类操作,所以并行也意味着需要多个 CPU
- 并发:同一时间处理多个任务。处理表示同一时间的多个任务中进行第 1 类操作的只有一个任务,其他任务都在进行第 2 类等待操作,所以并发不需要用到多个 CPU
# 同步与异步
r1 = func1() // 5 秒 | |
r2 = func2() // 3 秒 | |
r3 = func3() // 10 秒 |
- 同步:多个任务严格按照顺序执行
func2() 在 func1() 返回后执行, func3() 在 func2() 返回后执行
在下一调用执行前,会阻塞在当前调用
运行时间:5+3+10=18 秒
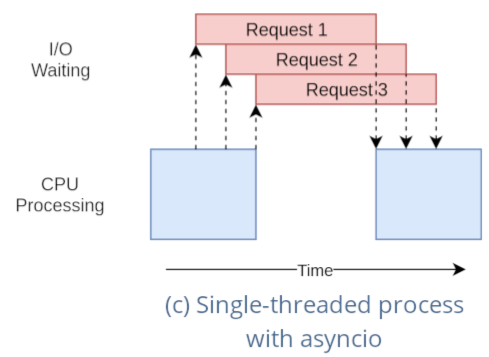
- 异步:在一段时间内多个任务交替执行
所有的 func() 都是立即返回,返回值是一个能够获取最终结果的对象
通过异步的方式也可以让多个 IO 的等待时间重叠,实现并发,从而加速整个任务的执行
运行时间:10 秒(没有其他因素影响)
# python 的协程标准库 asyncio
# 核心概念
# 事件循环 (Eventloop)
asyncio 的核心,中央总控
- 多线程:用户创建一个线程来执行某个函数。不同的线程之间的切换由操作系统来调度,操作系统来决定每一个线程什么时候执行、执行多久等,对用户是透明的
- 协程:事件循环相当于用户态的线程队列;用户将多个异步函数(也就是任务 Task)注册到事件循环上,事件循环会循环执行这些函数(同时只能执行一个)。当执行到某个函数时,如果它正在等待 I/O 返回,事件循环会暂停它的执行然后去执行其他的函数。用户可以明确地知道或者指定协程的执行状态、执行顺序等
# 协程 (Coroutine)
协程本质上就是一个函数,特点是在代码块中可以将执行权交给其他协程
import asyncio | |
async def a(): | |
print('Suspending a') | |
await asyncio.sleep(0) # 转让执行权 | |
print('Resuming a') | |
async def b(): | |
print('In b') | |
async def main(): | |
await asyncio.gather(a(), b()) # 将协程 a 和 b 注册到事件循环上执行 | |
if __name__ == '__main__': | |
asyncio.run(main()) |
// 运行结果
Suspending a
In b
Resuming a
async def声明的函数就是一个协程 (Python 3.5+)asyncio.gather是将协程注册到事件循环的其中一种方法,这里表示协同执行 a 和 b 两个协程await的作用是执行协程和其他的可等待对象(按字面意思理解就是等待这个函数执行结束,并且等待的期间可以让出执行权,让 cpu 去执行其他的协程); 协程如果直接调用(比如a(),b()前面不写await)返回的是 ** 协程对象,** 函数里面的代码并没有执行;await只能在协程内使用asyncio.run()用于启动事件循环 (Python 3.7+);因为在__name__ == '__main__'里不能使用await,所以需要将主函数也定义为协程,即async def main(),然后放到asyncio.run中执行
在 Python 3.6 及更早的版本,事件循环要通过下面的方式启动
if __name__ == '__main__': | |
loop = asyncio.get_event_loop() | |
loop.run_until_complete(main()) | |
loop.close() |
# Future
Future 代表一个「未来」对象,是对协程的封装,存放协程的执行状态、执行结果等
def c(): | |
print('In c') | |
return 12 | |
In : loop = asyncio.get_event_loop() | |
In : future = loop.run_in_executor(None, c) # run_in_executor () 返回 Future 对象 | |
In c | |
In : future # c 虽然已经执行,但是 future 的状态为 pending | |
Out: <Future pending cb=[_chain_future.<locals>._call_check_cancel() at /usr/lib/python3.9/asyncio/futures.py:384]> | |
In : await future # 实际上并不能在 async def 的函数之外使用 await | |
Out: 12 # await 后返回结果 | |
In : future # await 之后状态变为 finished | |
Out: <Future finished result=12> |
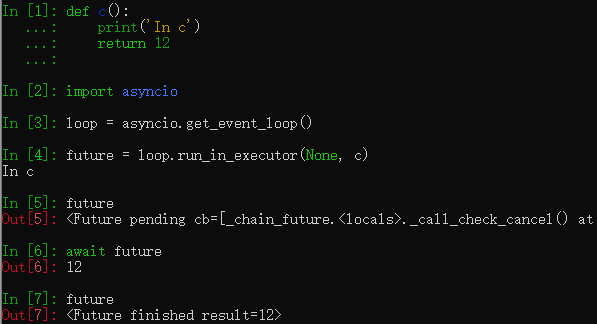
可以对 Future 实例操作,比如添加回调函数、取消任务、设置结果、设置异常等
# Task
实际开发中 Future 属于底层对象,一般不会直接使用,而是用 Future 的子类 Task
Future 仅仅是一个数据的容器, Task 则用于在事件循环中运行协程
async def set_after(fut): | |
# 创建一个协程,异步的 sleep 3 秒,然后给 future 对象设置结果 | |
await asyncio.sleep(3) | |
fut.set_result('Done') | |
In : loop = asyncio.get_event_loop() | |
In : fut = loop.create_future() # 在事件循环中创建一个 Future | |
In : fut # 此时它还是默认的 pending 状态,因为没有调用它 | |
Out: <Future pending> | |
In : task = loop.create_task(set_after(fut)) # 在事件循环中创建 (或者说注册) 了一个 Task | |
In : task # 马上输入它,此时刚创建任务,还在执行中 | |
Out: <Task pending name='Task-3044' coro=<set_after() running at <ipython-input-51-1fd5c9e97768>:2> wait_for=<Future pending cb=[<TaskWakeupMethWrapper object at 0x1054d32b0>()]>> | |
In : fut # 马上输入它,此时刚创建任务,还没有执行完所以 future 没有变化 | |
Out: <Future pending> | |
In : task # 过了三秒,任务执行完成了 | |
Out: <Task finished name='Task-3044' coro=<set_after() done, defined at <ipython-input-51-1fd5c9e97768>:1> result=None> | |
In : fut # Future 也已经设置了结果,所以状态是 finished | |
Out: <Future finished result='Done'> |
Future对象不是任务,loop.create_future()并不会执行函数的代码loop.create_task()则会让事件循环开始调度执行
# 基本用法
async/await 等异步操作是比较新的语法,使用的时候要注意 python 版本,建议使用 python 3.8+,旧版(3.6 及以前)的写法可能会有很大不同
整体逻辑:编写协程,在事件循环中创建任务,事件循环负责协程的协作调度执行
当一个任务等待一个 Awaitable 对象(协程、Future、Task 等)完成时,事件循环会运行其他任务、回调或执行 IO 操作
# asyncio.create_task()
在事件循环中创建一个 Task 一共有 3 种方法:
asyncio.create_task()loop.create_task()asyncio.ensure_future()
asyncio.create_task() 是 py3.7 引入的,底层还是用的 loop.create_task() ,推荐只用这一种
asyncio.ensure_future() 除了接收协程作为参数,还接收其他 Awaitable 对象
import asyncio | |
async def func(id): | |
print(f'Running new task id: {id}') | |
await asyncio.sleep(2) | |
print(f'Task {id} resuming') | |
return id | |
async def main(): | |
tasks = set() | |
for i in range(1, 5): | |
task = asyncio.create_task(func(i)) # 立即返回,此时已经开始执行,返回值是 Task 对象 | |
tasks.add(task) # 将 Task 对象添加至集合,方便管理 | |
await asyncio.wait(tasks) # 相当于 pool.join () | |
print(*[task.result() for task in tasks]) # Task 对象的结果要通过 result () 方法获取 | |
if __name__ == '__main__': | |
asyncio.run(main()) |
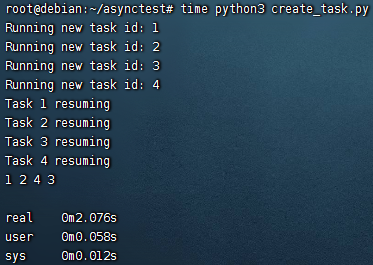
# asyncio.gather()
asyncio.gather() 的方法名说明了用途,用来「收集」传入的协程的执行结果,并且会按传入的协程顺序把来保存对应协程的执行结果
import asyncio | |
async def func(id): | |
print(f'Running new task id: {id}') | |
await asyncio.sleep(2) | |
print(f'Task {id} resuming') | |
return id | |
async def main(): | |
tasks = [func(i) for i in range(1, 5)] # 创建一个含有 4 个协程的列表 | |
results = await asyncio.gather(*tasks) # 在事件循环中创建任务执行协程,并等待结果 | |
print(results) # gather () 的返回值直接就是执行结果 | |
if __name__ == '__main__': | |
asyncio.run(main()) |
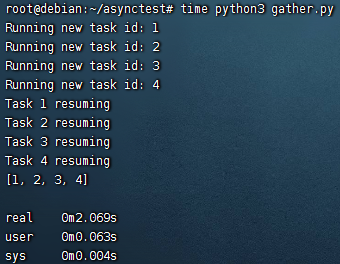
# gather() vs wait()
gather()可以把普通协程函数包装成Task对象,wait () 只能接收Task对象(Python 3.9 如果wait([a(), b()]会报 warning,提示在 3.11 中移除这种用法)gather()直接返回执行结果,wait()返回已完成和未完成的Task列表gather()有序,wait()无序
# Task 对象的高级用法
- 添加回调函数
def cb(future): | |
print(f'Result: {future.result()}') | |
async def main(): | |
tasks = set() | |
for i in range(1, 5): | |
task = asyncio.create_task(func(i)) | |
task.add_done_callback(cb) # 添加回调函数,执行完毕时输出结果 | |
tasks.add(task) | |
await asyncio.wait(tasks) |
- 设置任务超时
await asyncio.wait(tasks, timeout=10) |
# 错误用法
并不是用了 async / await 就能发挥 asyncio 的并发优势 ** **
async def a(): | |
await asyncio.sleep(3) | |
async def b(): | |
await asyncio.sleep(1) | |
async def main(): | |
await a() | |
await b() |
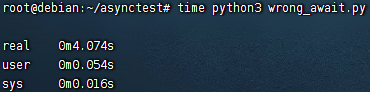
必须用 gather() 或者 create_task() 等方法将协程添加至事件循环,直接一个个 await 实际上是同步的
# CPU 密集型与 IO 密集型
def cpu_func(): | |
for i in range(100000): | |
for j in range(10000): | |
# do something | |
def io_func(url): | |
resp = requests.get(url) | |
r1 = io_func('http://xxx.com/500MB.bin') | |
r2 = io_func('http://xxx.com/100MB.bin') | |
r3 = io_func('http://xxx.com/256MB.bin') |
- 进程:资源分配的基本单位
- 线程:独立运行的基本单位,一个进程包含若干线程
- 协程:在一个线程里交替执行的任务
一般来说,选择多进程还是多线程取决于任务中哪一类的操作占比大:
- CPU 密集型任务:任务中需要大量的运算,没有阻塞,CPU 始终全速运行
- 例子:多层循环、视频编解码、矩阵运算
- 只有在真正的多核 CPU 上才可能通过多进程 / 多线程(由于 GIL 锁,Python 中只能是多进程)实现任务并行加速,在内存等其他条件允许的情况下,设置进程数 = CPU 核心数来避免进程切换,可以达到最大效率
- 单核 CPU 设置的多进程是模拟的,反而可能因为进程切换开销降低执行效率
- IO 密集型任务:任务的大部分时间 CPU 都在等待 I/O 操作完成,CPU 的消耗很少
- 例子:数据库交互、网络传输、硬盘读写
- 通过设置 CPU 核心数数倍的多线程来让多个任务的 IO 等待时间重叠,从而实现任务并发加速
- 线程数 = CPU 核数 / (1 - 阻塞系数),阻塞系数是 IO 等待时间占比,通常是 0.8~0.9
- 使用协程来实现并发,效率比多线程更高
现在的 CPU 基本上都有超线程技术,也就是 6 核 12 线程,8 核 16 线程等
通过将一个物理核心模拟出两个逻辑核心并行计算,并行的是线程
在代码层面进程数一般设置为物理核心数
# 3 种方案在 IO 密集型应用中的效率对比
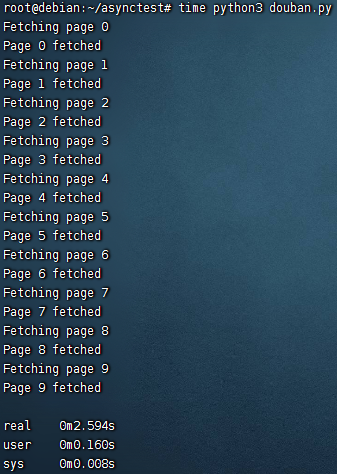
以一个最典型的 IO 密集型应用为例,爬豆瓣电影 top250(每页 25 个,一共 10 页),直接保存网页 html 文件
# 什么都不用的版本
import requests | |
url = 'https://movie.douban.com/top250?start=' | |
headers = { | |
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36' | |
} | |
def fetch(session, page): | |
print(f'Fetching page {page}') | |
resp = session.get(f'{url}{page*25}', headers=headers) | |
with open(f'download/top250-{page}.html', 'w') as f: | |
f.write(resp.text) | |
print(f'Page {page} fetched') | |
def main(): | |
with requests.Session() as session: | |
for p in range(10): | |
fetch(session, p) | |
if __name__ == '__main__': | |
main() |
# 多进程
from multiprocessing import Pool | |
def main(): | |
with Pool() as pool: | |
with requests.Session() as session: | |
pool.starmap(fetch, [(session, p) for p in range(10)]) |
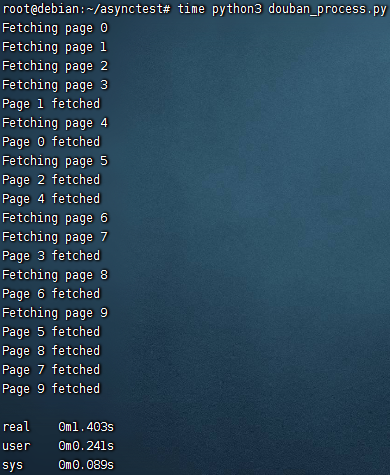
Pool() 不设置参数,默认开启与 cpu 核心数相同的进程数
4 核 cpu 启动 4 个进程,耗时 1.4s 左右
一般来说,多进程除了占用资源,没有什么明显缺点,只要机器性能足够强就可以更快
# 多线程
from multiprocessing.pool import ThreadPool | |
def main(): | |
with ThreadPool(processes=5) as pool: | |
with requests.Session() as session: | |
pool.starmap(fetch, [(session, p) for p in range(10)]) |
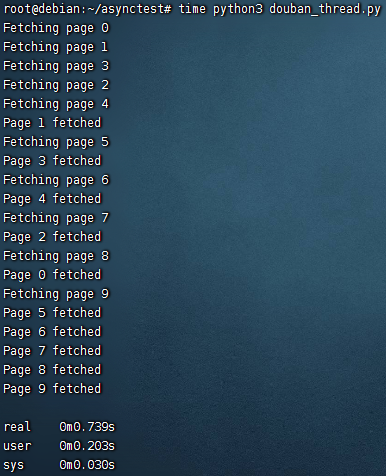
ThreadPool() 设置了线程数为 5,耗时 0.74s 左右
# GIL 锁
Python 为了解决线程安全(多线程的不确定性导致多个线程修改同一个变量)引入 GIL 锁
GIL 锁使得同一时间只有一个线程在 cpu 上执行(无论几个 cpu 核心,只要没有用多进程,就只会用到 1 个)
既然如此为什么多线程还可以提高并发效率?
- 一开始只有一个线程,不需要释放或者获得 GIL 锁
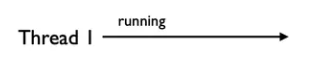
- 第 2 个线程被创建,因为初始没有 GIL 锁,所以被挂起
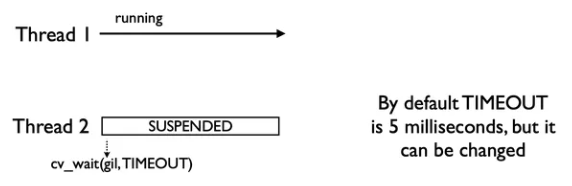
- 线程持有 GIL 锁的最长时间是
cv_wait周期(默认 5ms),在周期内如果出现了 I/O 阻塞就会提前释放 GIL 锁
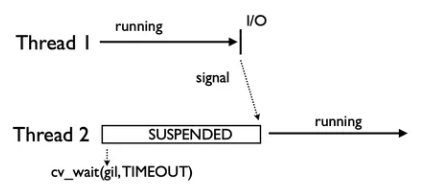
- 通过 GIL 的控制,每个线程都得到更好的执行时机
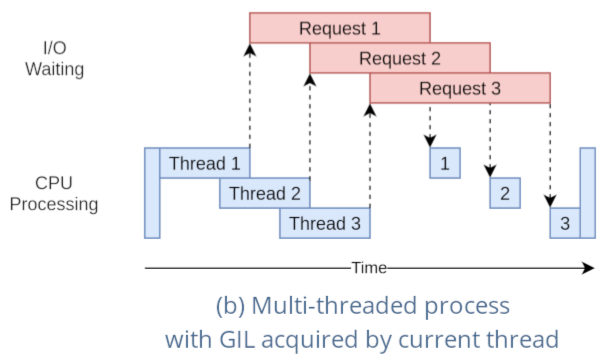
# 协程
在 asyncio 方案里,凡是涉及 I/O 阻塞操作的库都要使用 aio 生态中的库
所以 requests 要换成 aiohttp ,文件操作需要使用 aiofiles
# aiohttp
async with aiohttp.ClientSession() as session: | |
async with session.get('http://python.org') as resp: | |
status = resp.status | |
html = await resp.text() |
与 requests 的 session 写法非常类似,只是多了异步关键字
# aiofiles
async with aiofiles.open('1.text', 'w', encoding='utf-8') as fp: | |
await fp.write(data) |
基本用法除了加入异步关键字没有任何区别
import asyncio | |
import aiohttp | |
import aiofiles | |
async def fetch(session, page): | |
print(f'Fetching page {page}') | |
r = await session.get(f'{url}{page*25}', headers=headers) | |
async with aiofiles.open(f'download/top250-{page}.html', mode='w') as f: | |
await f.write(await r.text()) | |
print(f'Page {page} fetched') | |
async def main(): | |
loop = asyncio.get_event_loop() | |
async with aiohttp.ClientSession(loop=loop) as session: | |
tasks = [asyncio.create_task(fetch(session, p)) for p in range(10)] | |
await asyncio.wait(tasks) | |
if __name__ == '__main__': | |
asyncio.run(main()) |
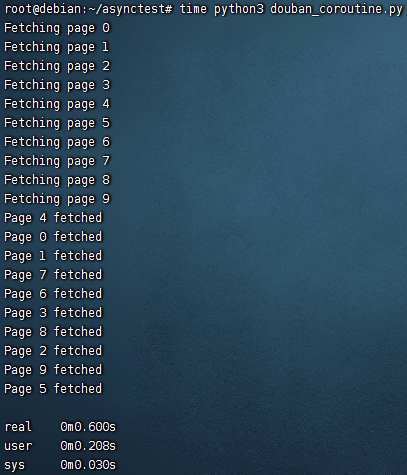
用时 0.6s 左右
asyncio 只要用的合理,普遍情况下是 3 种方案中最快的
在规模更大的应用中,asyncio 支持数千级别的活动连接,但是多线程在这个规模下可能会出现性能问题
# 总结
- 对于 cpu 密集型任务,(python) 多线程和协程不会带来效率提升,反而会在 cpu 持续运算的时候加入不必要的切换任务而影响效率
- 协程唯一的硬伤缺点就是它是单线程,无法利用多核 cpu,所以高并发的最佳做法其实是多进程 + 协程
- 协程使用单线程可能带来的问题是,如果代码没有写好,导致某个地方被阻塞,那么整个程序也会阻塞掉,但是多线程就不存在这一问题
- 很多教程(包括这个)在介绍 asyncio 的时候都用了
await asyncio.sleep()来模拟对 I/O 的等待,实际上程序里执行的任务远远不是 sleep 这么简单 网络请求需要用aiohttp,文件操作需要用aiofiles很多常用的 I/O 工具都有人开发了异步版本,aiomysql、操作 MongoDB 的motor、aioredis所以大多数情况下了解了最基本的异步语法,找到对应的库就已经足够 在没有造好的轮子的条件下,如何去实现这样的异步方法才是异步编程里面最复杂的地方