# 排名函数
以下表中的数据为例
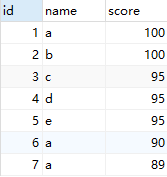
# rank()
RANK() OVER ( | |
PARTITION BY <expression>[{,<expression>...}] | |
ORDER BY <expression> [ASC|DESC], [{,<expression>...}] | |
) |
按照某一字段的排序结果添加跳跃、间断的排名
# row_number()
ROW_NUMBER() OVER ( | |
PARTITION BY <expression>[{,<expression>...}] | |
ORDER BY <expression> [ASC|DESC], [{,<expression>...}] | |
) |
从 1 开始分配序号
# dense_rank()
DENSE_RANK() OVER ( | |
PARTITION BY <expression>[{,<expression>...}] | |
ORDER BY <expression> [ASC|DESC], [{,<expression>...}] | |
) |
按照某一字段排序结果添加连续、不间断的排名
在不关心重复值的情况下(比如取第 N 大的值), dense_rank() 的效果也可以用 DISTINCT 配合 LIMIT 或 row_number() 或来实现
# 对比
SELECT score, rank() over(ORDER BY score DESC) as Rank FROM table1 |
rank() row_number() dense_rank() | |
+------+---------+ +-------+------+---------+ +------+---------+ | |
| score| Rank | |row_num| score| Rank | | score| Rank | | |
+------+---------+ +------ +------+---------+ +------+---------+ | |
| 100 | 1 | | 1 | 100 | 1 | | 100 | 1 | | |
| 100 | 1 | | 2 | 100 | 2 | | 100 | 1 | | |
| 95 | 3 | | 3 | 95 | 3 | | 95 | 2 | | |
| 95 | 3 | | 4 | 95 | 1 | | 95 | 2 | | |
| 95 | 3 | | 5 | 95 | 1 | | 95 | 2 | | |
| 90 | 6 | | 6 | 90 | 1 | | 90 | 3 | | |
| 89 | 7 | | 7 | 89 | 1 | | 89 | 4 | | |
+------+---------+ +-------+------+---------+ +------+---------+ |
# null 判断函数
# isnull(expr)
判断 expr 是否为 null :
- 是,返回 1
- 否,返回 0
# ifnull(expr1, expr2)
判断 expr1 是否为 null :
- 是,返回
expr2 - 否,返回
expr1
# nullif(expr1, expr2)
判断 expr1 = expr2 是否成立:
- 是,返回
null - 否,返回
expr1
# if(expr, value1, value2)
判断 expr 是否成立:
- 是,返回
value1 - 否,返回
value2
类似三元运算符 expr ? value1 : value2 或 Python 中的 a = value1 if expr else value2
# coalesce(value1, value2, ..., valueN)
返回多个值中第一个非 null 值
# N/A 处理
MySQL 中, null 表示空值,而 N/A 表示不存在这样的值
null 与任何值作比较 ( = < > ) 都返回 null ,而 N/A 可以进行 = 比较
# 嵌套一层查询
原查询返回结果 N/A
SELECT name FROM table1 WHERE id = 3 |
在外层嵌套一个 SELECT ,可以将结果转换为 null
SELECT ( | |
SELECT name FROM table WHERE id = 3 | |
) |
# 用 max () 或 min () 等函数转换
如果在 null 判断函数(如 ifnull() )中判断 N/A ,可以使用 max() 或 min() 函数将 null 转换为 N/A
SELECT ifnull(max(name), 'Example') FROM table1 |
# null 筛选
由于 null 与任何值的对比都返回 null ,所以在查询条件 WHERE 中无论使用 = 还是 != 都会将 null 过滤掉
可以使用以下几个运算符:
is null:列值为null返回trueis not null:列值不为null返回true<=>:安全等于,既可以判断普通数值相等,也可以判断是否为null
# 重复值处理
+----+---------+ | |
| id | email | | |
+----+---------+ | |
| 1 | a@b.com | | |
| 2 | c@d.com | | |
| 3 | a@b.com | | |
+----+---------+ |
# GROUP BY + HAVING
SELECT DISTINCT email | |
FROM Person | |
GROUP BY email | |
HAVING COUNT(1) > 1 |
思路比较易于理解,按对应字段分组,找出数量大于 1 的
但效率比较低
# 自连接
SELECT DISTINCT t1.email | |
FROM Person t1 JOIN Person t2 ON t1.email = t2.email | |
WHERE t1.id != t2.id |
若有重复值,自连接后会出现 id 不同的行
自连接由于会使用索引,效率比 GROUP BY + HAVING 高
# 找出连续出现 N 次的值
+----+-----+ | |
| id | num | | |
+----+-----+ | |
| 1 | 1 | | |
| 2 | 1 | | |
| 3 | 1 | Result: | |
| 4 | 2 | +-----------------+ | |
| 5 | 1 | | ConsecutiveNums | | |
| 6 | 2 | +-----------------+ | |
| 7 | 2 | | 1 | | |
+----+-----+ +-----------------+ |
首先 id 有可能是不连续的,先通过 row_number() 重新分配连续 id 值 ( serial )
SELECT id, num, row_number() over(ORDER BY id) as 'serial' FROM Logs |
| id | num | serial | | |
| -- | --- | ------ | | |
| 1 | 1 | 1 | | |
| 2 | 1 | 2 | | |
| 3 | 1 | 3 | | |
| 4 | 2 | 4 | | |
| 5 | 1 | 5 | | |
| 6 | 2 | 6 | | |
| 7 | 2 | 7 | |
然后再通过按 num 分组的 row_number() ,为每个数字分配在自己组内出现的序号
SELECT id, num, row_number() over(PARTITION BY num ORDER BY id) as 'groupserial' FROM Logs |
| id | num | groupserial | | |
| -- | --- | ----------- | | |
| 1 | 1 | 1 | | |
| 2 | 1 | 2 | | |
| 3 | 1 | 3 | | |
| 5 | 1 | 4 | | |
| 4 | 2 | 1 | | |
| 6 | 2 | 2 | | |
| 7 | 2 | 3 | |
对比两个临时表,如果某一个 num 连续出现时, serial - groupserial 将会是一个固定值
| id | num | serial | groupserial | serial - groupserial | | |
| -- | --- | ------ | ----------- | -------------------- | | |
| 1 | 1 | 1 | 1 | 0 | | |
| 2 | 1 | 2 | 2 | 0 | | |
| 3 | 1 | 3 | 3 | 0 | | |
| 5 | 1 | 5 | 4 | 1 | | |
| 4 | 2 | 4 | 1 | 3 | | |
| 6 | 2 | 6 | 2 | 4 | | |
| 7 | 2 | 7 | 3 | 4 | |
利用 GROUP BY + HAVING 找出 COUNT > 3 的 num 可以得到结果
SELECT DISTINCT t1.num as ConsecutiveNums | |
FROM ( | |
SELECT id, num, row_number() over(ORDER BY id) - row_number() over(PARTITION BY num ORDER BY id) as 'serialsub' | |
FROM Logs | |
) t1 | |
GROUP BY t1.num, serialsub | |
HAVING COUNT(1) >= 3 |
# 日期处理
MySQL 的 date 类型直接进行加减,会转换成数字类型加减
比如 '2023-01-01' - 1 = '2023-01-00' ,会出现错误
# DATE_ADD(date, INTERVAL expr type)
MySQL >= 8.0 可以使用别名 ADDDATE()
增加时间间隔,比如增加 1 天
DATE_ADD('2023-01-01', INTERVAL 1 day) |
type 可以是 day , month , year , week 等等
# DATE_SUB(date, INTERVAL expr type)
MySQL >= 8.0 可以使用别名 SUBDATE()
同上,减少时间间隔
# DATEDIFF(date1, date2)
返回 date1 与 date2 之间的间隔天数 ( date1 - date2 )
SELECT DATEDIFF('2023-01-02', '2023-01-01') as diff # 1 | |
SELECT DATEDIFF('2023-01-01', '2023-01-02') as diff # -1 |
SQL Server 中可以指定计算的单位: DATEDIFF(type, date1, date2)
SELECT DATEDIFF(year, '2023-01-01', '2020-01-01') as diff # 3 |
# COUNT() 按条件统计
COUNT(column_name) 统计的是 column_name 列中 ++ 不为 null ++ 的行数
如果只写条件,比如 COUNT(age >= 18) ,在 age 列没有 null 的情况下, age >= 18 返回的是 true 或 false ,都会被 COUNT() 统计进去,所以和 COUNT(*) 没有区别
因此 COUNT() 按条件统计需要添加 OR NULL ,即 COUNT(age >= 18 OR NULL)
# 小数保留
# ROUND(number, decimals)
四舍五入保留 number 的 decimals 位小数
SELECT ROUND(3.1415, 2) # 3.14 |
类似函数还有:
FLOOR(number):向下取整CEIL(number):向上取整TRUNCATE(number, decimals):直接截断至decimals位小数
# CAST(expr AS datatype) + Decimal(m, d)
CAST() 函数本身用于数据类型转换,也可以用来实现小数保留
Decimal(m, d) 中, m 指数字的最大位数 ( 1 ~ 65 ,默认为 10 ), d 指小数点后的位数 ( 0 ~ 30 ,默认为 0 ),并且 d <= m
例子:
Decimal(5, 2):-999.99~999.99,小数点后2位,总共5位Decimal(7, 6):-9.999999~9.999999,小数点后6位,总共7位
SELECT CAST(3.1415, Decimal(10, 2)) # 3.14 |
CAST() + Decimal() 转换小数默认为四舍五入